MCUの DAC( Digital to Analog Converter )を使用して発声を行う機能です。発声は 音声合成ライブラリを使用しています。
◀ この記事の前に: 発音・発声( DAC出力 )
▶ この記事の次に:
発声の概要
発声は Peripheral MCUの DAC出力で行います。発声は ESP32向けの音声合成ライブラリである AquesTalk-ESP32 Ver.2.0( 株式会社アクエスト )を使用しています。
AquesTalk-ESP32 Ver.2.0 の特徴
・テキストからの音声合成
テキスト情報からリアルタイムに音声を生成します。録音タイプの音声合成と違い、その都度ナレーターの声を収録する必要がありません。
・超小型・最軽量
他に類を見ない小ささの音声合成エンジン。ROM 28KB、RAM 500B から動作します。
・耳なじみの良い声
聴きやすさや明瞭性を重視し、人の声にこだわらない高品質な音声を合成します。
・実装が簡単
ANSI C言語準拠のコードで記述されています。外部ライブラリやファイルシステムを使わないため、OSを持たない環境へも簡単に移植・実装できます。
引用: AquesTalk ESP32 / 株式会社アクエスト
音声合成ライブラリ
音声合成ライブラリの仕様
音声合成ライブラリ( AquesTalk-ESP32 Ver.2.0 )の仕様は以下のとおりです。
Qumcum Lab. の入力データ形式は「ローマ字表記音声記号列( ASCII )」、必要メモリサイズは「ROM:約28KB, RAM:約500B ( 音声記号列からの合成のみの場合 )」です。
| ライブラリ形式 | ESP32 用static ライブラリ |
| 動作確認環境 | Arduino core for ESP32、 ESP-IDF |
| 入力データ形式 | 漢字仮名交じりテキスト( UTF8 / UTF16LE ) または、ローマ字表記音声記号列( ASCII ) |
| 出力データ形式 | WAV フォーマット( 8KHz サンプリング,16bitPCM,モノラル )データ *24KHzサンプリングにアップサンプリング機能を含む |
| 声種 | picoF4 Rev.2 |
| 関数I/F | C 関数呼び出し |
| 必要メモリサイズ | ROM:約200KB, RAM:約21KB ( 漢字仮名交じり文からの合成の場合 辞書データ別途 ) ROM:約28KB, RAM:約500B ( 音声記号列からの合成のみの場合 ) |
引用: AquesTalk ESP32 / 株式会社アクエスト
音声合成ライブラリのライセンス
この音声合成ライブラリはライセンス( 有償 )が必要です。
サンプルプログラムはライセンスを取得して使用しています。Peripheral MCUの改造を行う場合、ライセンスキーの設定( コードへの組み込み )が必要です。
ライセンスに関してはこちらをご覧ください。
ESP32 の MACアドレスの取得方法( ご注意 )
前項のライセンスに関する記載の中に「ライセンスキーの入手」が書かれています。ライセンスキーは音声合成ライブラリを搭載する ESP32の MACアドレスが必要になります。ESP32の MACアドレスを調べる方法も記載されています。このコードではエラー( ‘ESP_MAC_BT’ was not declared in this scope’ESP_MAC_BT’ was not declared in this scope )が生じます。
ESP32の MACアドレスは以下の記事に記載の方法で取得できます。
・ESP32のWiFiやBluetoothのMACアドレスを調べる方法: Qiita / @Kurogara
コードを書き込み後にシリアルモニタを開き、再起動することにより MACアドレスなどをモニタに表示します。
発音のデータ( 文字列 )
音声合成ライブラリで発音に使用する文字列は以下の二つの方法があります。
- 漢字を含む任意の文
- 音声記号列
音声合成ライブラリは、言語処理部( AqKanji2Koe )と規則音声合成部( AquesTalk )で構成されています。漢字を含む任意の文は、言語処理部に入力することにより音声記号列に変換できます。音声記号列を規則音声合成部に入力することにより音声波形に変換できます。
Qumcum Lab. は規則音声合成を使用します。サンプルプログラムは容量などの関係から言語処理部を搭載していません。( 言語処理部は辞書データが必要で、容量が大きいため SDメモリなどに搭載する必要があります。)
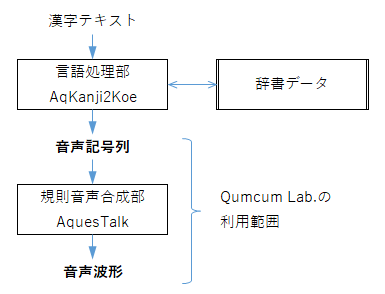
音声記号列はローマ字とイントネーションを表す記号で構成した ASCII文字列です。
音声記号列の詳細は以下をご覧ください。
・ローマ字音声記号列仕様書: 発音のデータ(文字列)の仕様書 / 株式会社 アクエスト
発声処理の手順
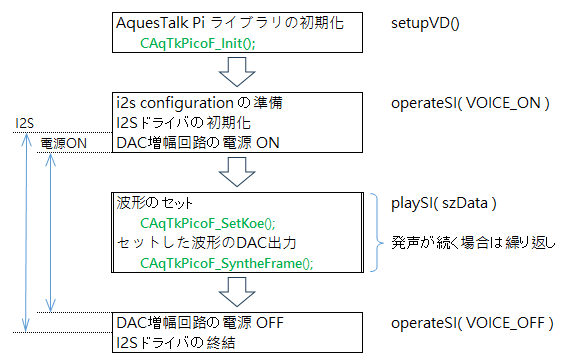
発声処理には音声合成ライブラリ( AquesTalk-ESP32 Ver.2.0 )と、ESP32の DACを動作させるための I2Sライブラリを使用します。
初期化は AquesTalkの初期化( CAqTkPicoInit() )で行います。発声時は I2Sと DACの出力波形を増幅する DAC増幅回路の電源の準備を行います。発声終了時は I2SのリリースとDAC増幅回路の電源を OFFにします。発声は、AquesTalkの波形のセット( CAqTkPicoF_SetKoe() )とセットした波形の DAC出力( CAqTkPicoSyntheFrme() )を発声が続くまで繰り返し実行します。
発音は Voice driverが担い、全体の制御は Speak interpreterが行います。
いずれの処理も APIでアプリケーションなど外部から操作できる関数を持ち、その関数を介して操作します。
発声時だけ DAC増幅回路の電源の ONにしますので省電力化を実現できます。
音声合成ライブラリに関する情報
音声合成ライブラリ( AquesTalk-ESP32 Ver.2.0 )に関する情報は以下をご覧ください。
- 音声合成エンジン: AquesTalk picoの概要 / 株式会社 アクエスト
- ダウンロード: マニュアル、評価版ライブラリ、他をダウンロードできます / 株式会社 アクエスト
当該ページの「その他」の「AquesTalk ESP32」です。 - AquesTalk ESP32 マニュアル: ESP32用の音声合成ライブラリの説明書 / 株式会社 アクエスト
前項でダウンロードした中に含まれています。 - ローマ字音声記号列仕様書: 発音のデータ(文字列)の仕様書 / 株式会社 アクエスト
- オンラインデモ: 音声のデモをきくことができます / 株式会社 アクエスト
規則音声合成のデモで音声記号列を作ることもできます。 - AquesTalk ESP32をかんたんに使う(ESP32 1.0.4編): わかりやすい使用例です / Lang-ship
- ESP32で音声合成(AquesTalk pico for ESP32): 使用例です / N.Yamazaki’s blog
- ESP32のI2Sを使ったDAC出力研究: 使用例です / N.Yamazaki’s blog
- 「AquesTalk-ESP32 Ver.2.4」を使う: 使用例です。 / N.Yamazaki’s blog
- AquesTalk ESP32 の辞書を内蔵Flashに書き込んで使う: 使用例です / N.Yamazaki’s blog
- サンプルプログラム: Qumcum Lab.で動作します / Github tanakamasayuki/aquestalk
hello_aquestalk.ino - ESP32でサウンド出力時のクリックノイズ対策(I2S+内蔵DAC) / N.Yamazaki’s blog
参考情報
参考になる情報は以下のとおりです。
このホームページ内
- 発音・発声( DAC出力 / ハードウエア ): MCUの DACを使用して発音や発声を行うハードウエアを説明します。
- Speak interpreter ( 概要 ): 発声処理の最上位、Speak interrupter の概要です。
- Speak interpreter( 操作説明 ): アプリケーションからの操作方法です。( API )
- Speak interpreter( コード ): コードの詳細を説明します。
- Voice driver( 概要 ): 発音そのものの処理です。( API )
- Voice driver( 操作説明 ): 個々のサーボモータを制御する方法です。
- Voice driver( コード ): コードの詳細を説明します。
- 音声合成ライブラリ: ライブラリの概要や導入方法を説明します。
